正则表达式
元字符
| 分类 | 符号 | 含义 |
|---|---|---|
| 特殊单字符 | . |
任意字符(换行除外) |
| 特殊单字符 | \d |
任意数字 |
| 特殊单字符 | \D |
任意非数字 |
| 特殊单字符 | \w |
任意字母数字下划线 |
| 特殊单字符 | \W |
任意非字母数字下划线 |
| 特殊单字符 | \s |
任意空白符 |
| 特殊单字符 | \S |
任意非空白符 |
| 分类 | 符号 | 含义 |
|---|---|---|
| 空白符 | \r |
回车符 |
| 空白符 | \n |
换行符 |
| 空白符 | \f |
换页符 |
| 空白符 | \t |
制表符 |
| 空白符 | \v |
垂直制表符 |
| 空白符 | \s |
任意空白符 |
| 分类 | 符号 | 含义 |
|---|---|---|
| 量词 | . |
0 到多次 |
| 量词 | + |
1 到多次 |
| 量词 | ? |
0 到 1 次 |
| 量词 | {m} |
出现 m 次 |
| 量词 | {m,} |
出现至少 m 次 |
| 量词 | {m,n} |
出现 m 到 n 次 |
| 分类 | 符号 | 含义 |
|---|---|---|
| 范围 | | |
或,如 ab|bc 代表 ab 或 bc |
| 范围 | [...] |
多选1,括号中任意单个元素 |
| 范围 | [a-z] |
匹配 a 到 z 之间任意单个元素 |
| 范围 | [^...] |
取反,不能是括号中任意单个元素 |
贪婪模式
量词
| 符号 | 同义符号 | 含义 | 示例 |
|---|---|---|---|
* |
{0,} |
0 到多次 | ab* 可以匹配 a、ab、abb 等 |
+ |
{1,} |
1 到多次 | ab+ 可以匹配 ab、abb 等,但不能匹配 a |
? |
{0,1} |
0 到 1 次 | ab? 可以匹配 a、ab,但不能匹配 abb |
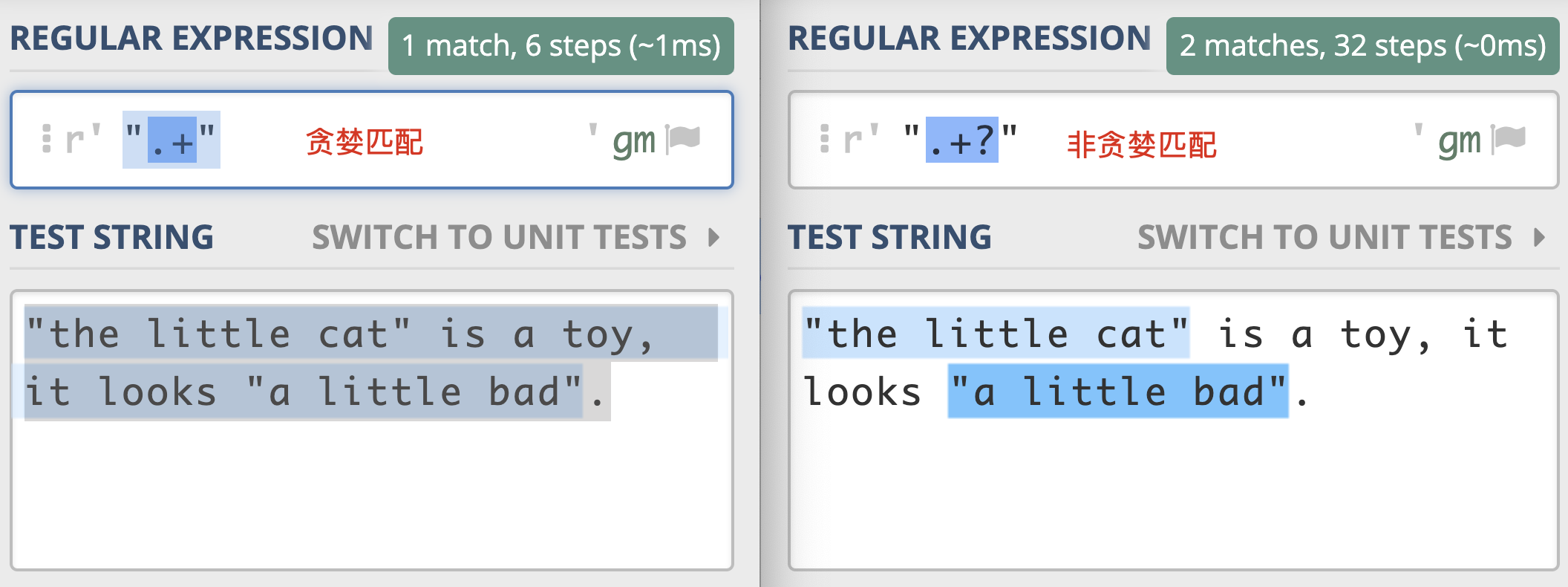
贪婪匹配(Greedy)
尽可能进行最长匹配
用法:贪婪匹配为默认模式,如 a*
匹配不上会回溯
字符串 aaabb
下标 012345
| 匹配 | 开始 | 结束 | 说明 | 匹配内容 |
|---|---|---|---|---|
| 第1次 | 0 | 3 | 到第一个字母b发现不满足,输出aaa | aaa |
| 第2次 | 3 | 3 | 匹配剩下的bb,发现匹配不上,输出空字符串 | 空字符串 |
| 第3次 | 4 | 4 | 匹配剩下的b,发现匹配不上,输出空字符串 | 空字符串 |
| 第4次 | 5 | 5 | 匹配剩下空字符串,输出空字符串 | 空字符串 |
懒惰匹配(Lazy)
尽可能进行最短匹配
用法:在贪婪匹配后加 ?,如 a*?
匹配不上不会回溯
独占匹配(Possessive)
与贪婪模式类似,尽可能进行最长匹配,如果匹配失败就结束,
不会进行回溯,比较节省时间。
用法:“数量”元字符后加 + 。如 a*+
| 模式 | 正则 | 文本 | 结果 |
|---|---|---|---|
| 贪婪模式 | a{1,3}ab |
aaab |
匹配 |
| 非贪婪模式 | a{1,3}?ab |
aaab |
匹配 |
| 独占模式 | a{1,3}+ab |
aaab |
不匹配 |
后面匹配不上,会吐出已匹配的再尝试

分组与引用
- 将某部分(子表达式)看成一个整体
- 在后续查找或替换中引用分组
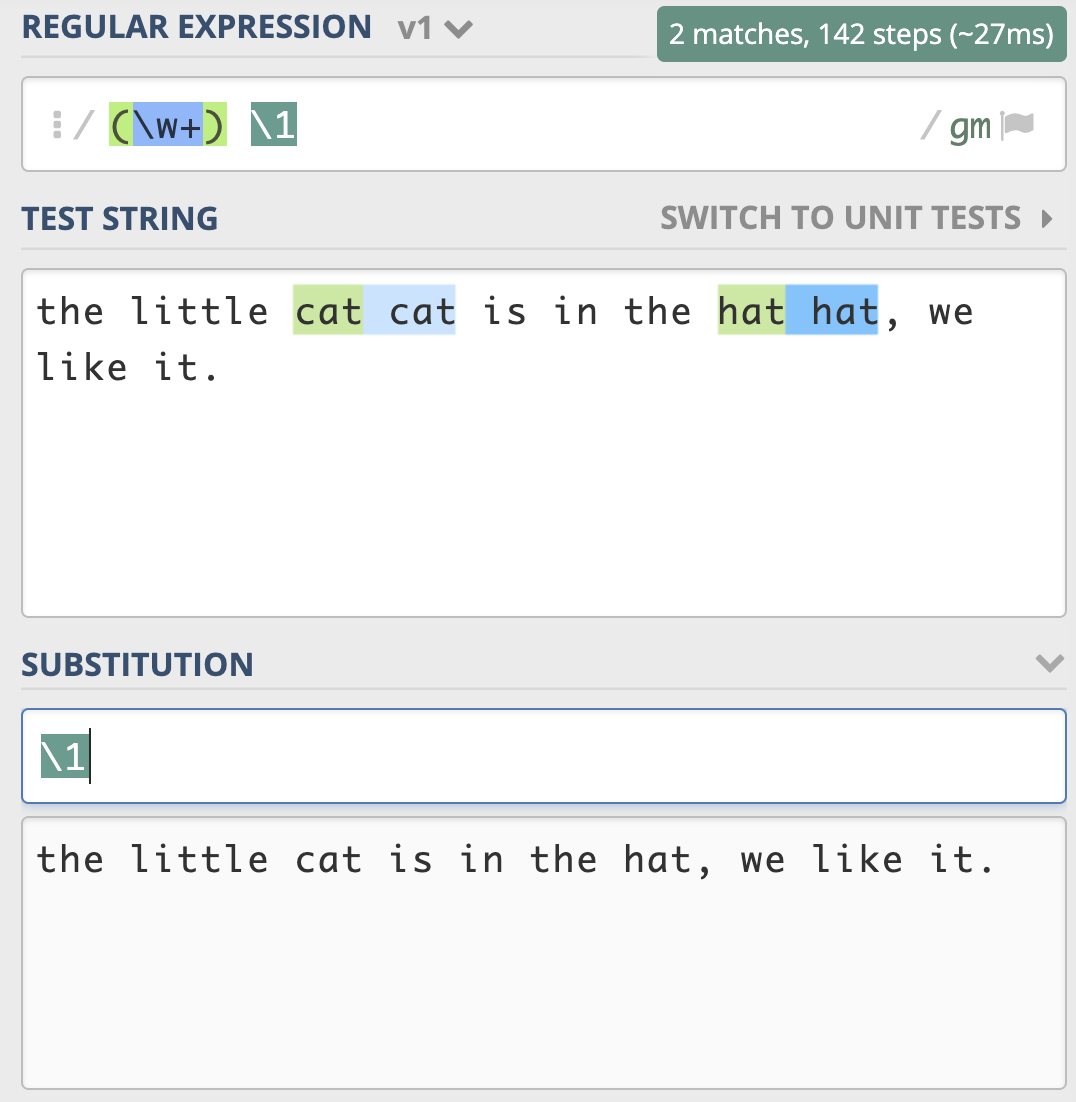
分组与编号
括号在正则中可以用于分组,被括号括起来的部分“子表达式”会被保存成一个子组。第几个括号就是第几个分组。

非捕获分组
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它。
用法:在括号中使用 ?:
| 类型 | 正则 | 示例 |
|---|---|---|
| 保存子组 | (正则) |
\d{15}(\d{3})? |
| 不保存子组 | (?:正则) |
\d{15}(?:\d{3})? |
命名分组
命名分组的格式为 (?P<分组名>正则)
^profile/(?P<username>\w+)/$
引用分组
|

|
匹配模式
匹配模式(Match Mode):指的是正则中一些改变元字符匹配行为的方式,通过模式修饰符来指定
用法:(?模式标识)正则表达式
可以将多种模式标识放一起 (?标识1标识2)正则表达式
可通过添加括号来改变模式标识作用范围
不区分大小写模式(Case-Insensitive)
用法:正则前添加模式修饰符 (?i)
例:
(?i)cat 不区分大小写的 cat,同 [Cc][Aa][Tt]
匹配两个 cat 时:
| 正则 | 效果 |
|---|---|
(?i)(cat) \1 |
可以匹配前后大小写不同,即 (?i) 范围包扩 \i |
((?i)cat) \1 |
前后大小写必须相同,限制了 (?i) 的范围 |
((?i)(cat)) \1 |
会多出一个子组,和 ((?i)(cat)) \2 效果一样 |
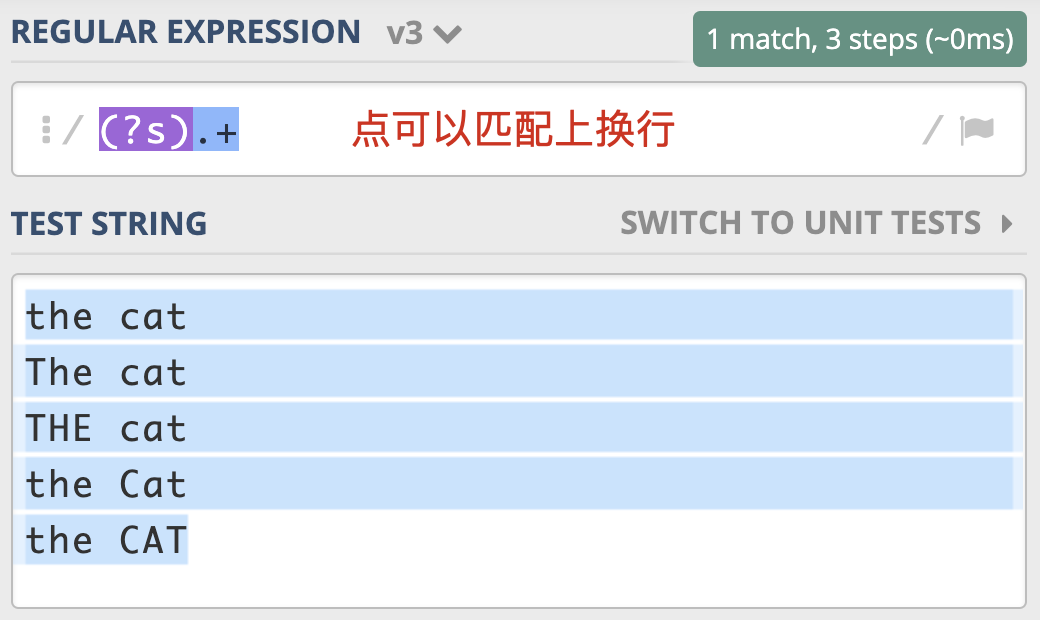
点号通配模式(Dot All)
也叫单行匹配模式(Single Line)
用法:正则前添加模式修饰符 (?s)
通常 . 不能匹配换行符,使用点号通配模式可以匹配上换行符
也可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等实现匹配真正任意字符
多行匹配模式(Multiline)
用法:正则前添加模式修饰符 (?m)
通常 ^ 匹配整个字符串的开头, $ 匹配整个字符串的结尾
多行匹配模式下会匹配每行的开头或结尾

正则中还有\A 仅匹配整个字符串的开始,\z 仅匹配整个字符串的结束,在多行匹配模式下,它们的匹配行为不会改变,如果只想匹配整个字符串,而不是匹配每一行,用这个更严谨一些。
注释模式(Comment)
正则中书写注释
用法 (?#comment)
例:
(\w+) \1 添加注释后 (\w+)(?#word) \1(?#word repeat again)
断言
单词边界(Word Boundary)
用法:正则中使用\b 来表示单词的边界
tom 单词包含 tom |
\btom 以 tom 开头的单词 |
tom\b 以 tom 结尾的单词 |
\btom\b 只能是 tom |
|
|---|---|---|---|---|
tom |
✅ | ✅ | ✅ | ✅ |
tomorrow |
✅ | ✅ | 🚫 | 🚫 |
atom |
✅ | 🚫 | ✅ | 🚫 |
atomic |
✅ | 🚫 | 🚫 | 🚫 |
\b\w+\b 匹配单词,或者空格分隔的字符串等
行的开始或结束
用法:使用 ^和 $匹配行的开始或结束(多行匹配模式)\A和 \z匹配整个字符串的开始或结束,不受匹配模式的影响。
例如:^\d{6}$匹配六位数字
各平台换行符:
| 平台 | 换行符号 |
|---|---|
| Windows | \r\n |
| Linux | \n |
| macOS | \n |
环视( Look Around)
也称零宽断言
用法:
| 正则 | 名称 | 含义 | 示例 |
|---|---|---|---|
(?<=Y) |
肯定逆序环视 (Positive Lookbehind) | 左边是Y | (?<=\d)th 左边是数字的th, 能匹配 9th |
(?<!Y) |
否定逆序环视 (Negative Lookbehind) | 左边不是Y | (?<!\d)th 左边不是数字的th, 能匹配 health |
(?=Y) |
肯定顺序环视 (Positive Lookahead) | 右边是Y | six(?=\d) 右边是数字的six, 能匹配 six6 |
(?!Y) |
否定顺序环视 (Negative Lookahead) | 右边不是Y | hi(?!\d) 右边不是数字的hi, 能匹配 high |
口诀:
- 左尖括号代表看左边
- 没有尖括号是看右边
- 感叹号是非的意思
表示环视的括号不算做子组
例子:
匹配邮政编码(?<!\d)[1-9]\d{5}(?!\d)
匹配单词(?<!\w)\w+(?!\w)``(?<=\W)\w+(?=\W)``\b\w+\b
JavaScript 不支持逆向环视(逆向断言)