锁库大师
背景
希望在顾客下单时对库存明细表中的商品进行库存锁定,库存明细表简化后如下所示:
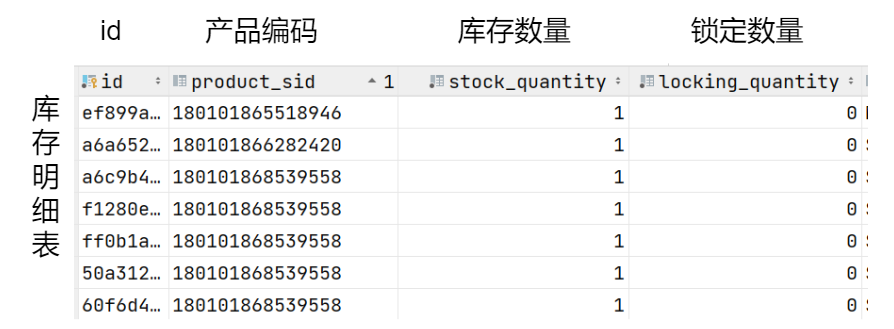
可见一条产品编码有可能存在多条库存明细,客户的订单大致会锁定几十行的库存,要求如下:
- 尽可能快,并发也高,支持多节点
- 为了数据的一致性,最好不用 redis 扣减的方案
- 锁库同时在锁库流水表中插入锁库记录
优化方案
分析
通过分析系统现有的方案,发现锁库操作时间主要浪费在更新库存明细的锁库数量上,为了防止超卖,每一条更新必须加上库存校验(如下所示),一旦失败就要回滚,在加之 MySQL 并没有提供原生批量更新方法,只能每行库存执行一条 SQL,导致锁库时间较长。
WHERE (stock_quantity - locking_quantity) > 0
提高锁库速度
优化的第一步就是想要提高批量锁库的速度,有没有方法能够在 MySQL 中模拟批量更新呢?
WHEN 语句
答案就是使用 SQL 的 when 语句,在程序中拼接出如下的 SQL
UPDATE p_stock_instance a
SET a.locking_quantity = CASE a.id
WHEN '027dbba9c04a4ef0baab3983c64bc0b31123' THEN 3
WHEN '025d4574cd934b69993703e7e99e8ca43' THEN 6
WHEN '027dbba9c04a4ef0baab3983c64bc0b313' THEN 2 END,
a.update_date = now()
WHERE CASE a.id
WHEN '027dbba9c04a4ef0baab3983c64bc0b31123' THEN (a.stock_quantity - a.locking_quantity) >= 3
WHEN '025d4574cd934b69993703e7e99e8ca43' THEN (a.stock_quantity - a.locking_quantity) >= 6
WHEN '027dbba9c04a4ef0baab3983c64bc0b313' THEN (a.stock_quantity - a.locking_quantity) >= 2
ELSE 0 END;
SQL 执行完毕后会返回更新行数,在程序中判断更新行数是否与预期相符即可判断是否更新成功,程序示意如下:
Integer num = pStockInstanceDao.operationStockSmallData(operationMapping);
if (num != operationMapping.size()) {
throw new RuntimeException("操作失败");
}
这种方法的更新速度很快,在我的测试中,更新两万行库存记录的耗时大约 17 秒。但其实还有更快的方法。
临时表
使用临时表更新库存的方法在数据量比较大的情况下比 WHEN 语句的性能好很多,测试条件下更新两万行库存记录耗时大约 1 秒
临时表是 MySQL 中的一种特殊表,他有如下几个特征:
- 临时表是线程内可见,线程之间看不到其他线程创建的临时表
- 线程推出后临时表就被销毁
- 临时表与普通表重名时 MySQL 优先选择临时表操作
本案例中创建临时表的语句如下:
create temporary table temp_stock_operation
(
stock_instance_id varchar(64) unique not null comment '库存实例ID',
op_num int not null comment '操作数量',
success tinyint(1) default 0 not null comment '是否成功'
);
stock_instance_id 就是库存明细表中的 id
更新库存时:
- 创建临时表
- 先将每一行库存明细要锁定的库存数量插入到临时表中
- 然后通过 UPDATE JOIN 语句批量更新库存,同时将是否更新成功的信息保存在临时表的
success字段中 - 统计
success字段,判断是否回滚 - 删除临时表
使用的 UPDATE 语句如下:
update temp_stock_operation o inner join p_stock_instance s
on o.stock_instance_id = s.id
set o.success = 1,
s.locking_quantity = s.locking_quantity + o.op_num
where s.stock_quantity - s.locking_quantity >= o.op_num
and o.success = 0;
检查是否成功,该语句返回值为 0 或 1 。
select count(*) = 0 as success
from temp_stock_operation
where success = 0;
最后删除临时表:
drop temporary table temp_stock_operation;
将二者结合
虽然使用临时表的方案更新大量数据时很快,但是如果使用这个方法来更新几十条库存时就会发现速度又变慢了,在我的测试中,更新三四十条的耗时几乎与更新两万条相等。
就是说这条更新语句在数量少的时候性能会下降
update temp_stock_operation o inner join p_stock_instance s
on o.stock_instance_id = s.id
set o.success = 1,
s.locking_quantity = s.locking_quantity + o.op_num
where s.stock_quantity - s.locking_quantity >= o.op_num
and o.success = 0;
分析它的执行计划,发现当更新行数小于 45 时,JOIN 操作便不会走索引,而是全表扫描,导致性能下降。这时候即使使用下面的 SQL 语句强制索引也是没用的。
update temp_stock_operation o force index for join (stock_instance_id)
inner join p_stock_instance s
on o.stock_instance_id = s.id
set o.success = 1,
s.locking_quantity = s.locking_quantity + o.op_num
where s.stock_quantity - s.locking_quantity >= o.op_num
and o.success = 0;
所以我们要将这两种方法结合,来获得最佳的性能
if (operationMapping.size() < 45) {
// WHEN 语句方案
Integer num = pStockInstanceDao.operationStockSmallData(operationMapping);
if (num != operationMapping.size()) {
throw new RuntimeException("操作失败");
}
} else {
// 临时表方案
Boolean success = pStockInstanceDao.operationStockBigData(operationMapping);
if (!success) {
throw new RuntimeException("操作失败");
}
}
提高并发量
由于并发时多个线程间存在竞态条件,可能导致库存扣减失败,而前面说到库存明细表中一件商品可能对应多条库存明细,就是说如果并发导致有一条库存明细扣减失败的话很可能这个商品在其他的库存明细中还有库存。而且由于无论更没更新成功,线程都会占有数据库行的写锁,这就要求我们更新失败时最好能够快速释放锁,这又会导致接口会误报库存不足。
商品编码锁
一个解决办法如下
- 线程在执行库存数量查询前为订单中的每个商品编码获取一个分布式锁,只有获得全部商品编码的锁时才进行库存的查询操作
- 线程在更新完库存后释放所持有的商品编码锁
RLock[] locks = productSids.seream()
.distinct()
.map(key -> "ced:pStockInstance:" + key)
.sorted()
.map(key -> redissonClient.getLock(key))
.toArray(RLock[]::new);
RLock skuLock = redissonClient.getMultiLock(locks);
// 加锁
skuLock.lock();
// 解锁
skuLock.unlockAsync();
这种方法当所有的订单都锁定同一个商品时就会导致程序退化成串行执行,效率很慢。
和并请求
由于前文我们已经将库存更新的方法优化的足够快,因此想高效地解决竞态条件的问题,可以将各个请求的参数在应用程序中合并在一起,然后使用一个线程批量扣减,从而避免线程间扣减冲突。
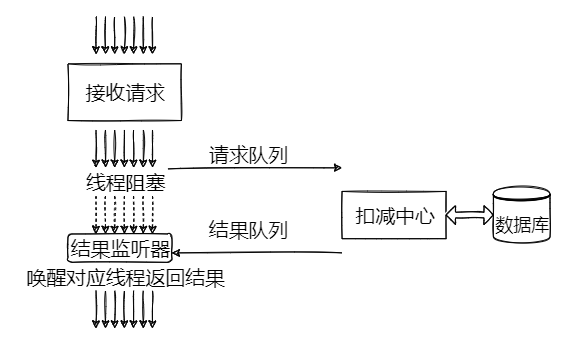
使线程阻塞并被唤醒的关键代码如下
public class GuardedObject<T, K> {
//受保护的对象
T obj;
final Lock lock = new ReentrantLock();
final Condition done = lock.newCondition();
final int timeout = 60;
//保存所有GuardedObject
final static Map<Object, GuardedObject> gos = new ConcurrentHashMap<>();
public GuardedObject(K key) {
this.key = key;
}
K key;
// 1. 被请求线程通过唯一 key 获得阻塞对象,然后将 key 存入消息,发送到扣减中心
public static <K> GuardedObject create(K key) {
GuardedObject go = new GuardedObject(key.toString());
gos.put(key, go);
return go;
}
// 2. 被请求线程稍后调用阻塞对象的该方法,阻塞,等待被唤醒
public Optional<T> get(Predicate<T> p) {
lock.lock();
Long start = System.currentTimeMillis();
try {
while (!p.test(obj)) {
done.await(timeout, TimeUnit.SECONDS);
if (System.currentTimeMillis() - start >= timeout * 1000) {
gos.remove(key);
break;
}
}
return Optional.ofNullable(obj);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
// 3. 结果监听器根据结果消息中的 key 找到对应阻塞对象,传入结果并唤醒对应线程
public static <K, T> void fireEvent(K key, T obj) {
GuardedObject go = gos.remove(key);
if (go != null) {
go.onChanged(obj);
}
}
//事件通知方法
void onChanged(T obj) {
lock.lock();
try {
this.obj = obj;
done.signalAll();
} finally {
lock.unlock();
}
}
}
性能测试
实验环境为了获得最坏情况下的性能,在库存明细中存入了两万五千条同一商品,并将每一条的数据的库存数量设置为 1
在我的电脑中启动两个服务接收请求,启动若干线程对该商品进行扣减,结果如下
| 请求线程数量 | 总计锁库行数 | 全部处理耗时 |
|---|---|---|
| 100 | 1000 | 1 S |
| 500 | 5000 | 3 S |
| 1000 | 10000 | 4 S |
| 2000 | 20000 | 8 S |
| 3000 | 25000 | 12 S |
注意事项
以下是我在编写代码时发现的一些需要注意的点:
唯一索引
在创建临时表时 stock_instance_id 要创建唯一索引,因为这个字段要充当 JOIN 语句的条件,实测不加唯一索引性能会很差。
create temporary table temp_stock_operation
(
stock_instance_id varchar(64) unique not null comment '库存实例ID',
加快消息队列读取
扣减中心的库存扣减线程直接从消息队列读取消息效率较低,在本案例中,可以新建一个本地队列,用其他线程将消息队列中的消息搬运到本地队列,让扣减线程操作本地队列而不是消息队列,这样可以大幅提高扣减效率。