AI 是如何学会聊天的
本文详细介绍了 AI 聊天模型的学习过程,从获取语料库、文本分词、预训练模型,到如何将基础模型转变为能够对话的 Chat 模型。同时讨论了上下文理解、模型幻觉等关键概念,以及如何通过搜索功能来增强模型的实时性和准确性。
获取语料库
在训练一个AI模型之前,首先需要准备大量的“语料”——即各种文本数据。这些文本数据来源于互联网上的网页、书籍、文章、社交媒体等。可以将这些数据看作是为AI模型提供的“学习材料库”,它将从这些材料中学习语言和知识。
例如,下面这个语料库从互联网抓取了51.3 TB(太字节)的文本数据。虽然这一数据量庞大,但它仅仅是一个起点,AI需要利用这些数据来理解词语、句子、语法等基本的语言规则。

Tokenization(分词)
抓取到大量文本后,我们不能直接让模型理解这些文字,因为计算机无法像人类一样“阅读”这些内容。为了让模型理解,我们需要将文本转换为数字,这一过程称为“分词”(Tokenization)。
在分词过程中,每一个单词、符号,甚至空格都会被转换为数字。可以将其理解为为每个词语和符号分配一个唯一的ID,这样计算机就能通过这些数字来处理语言。
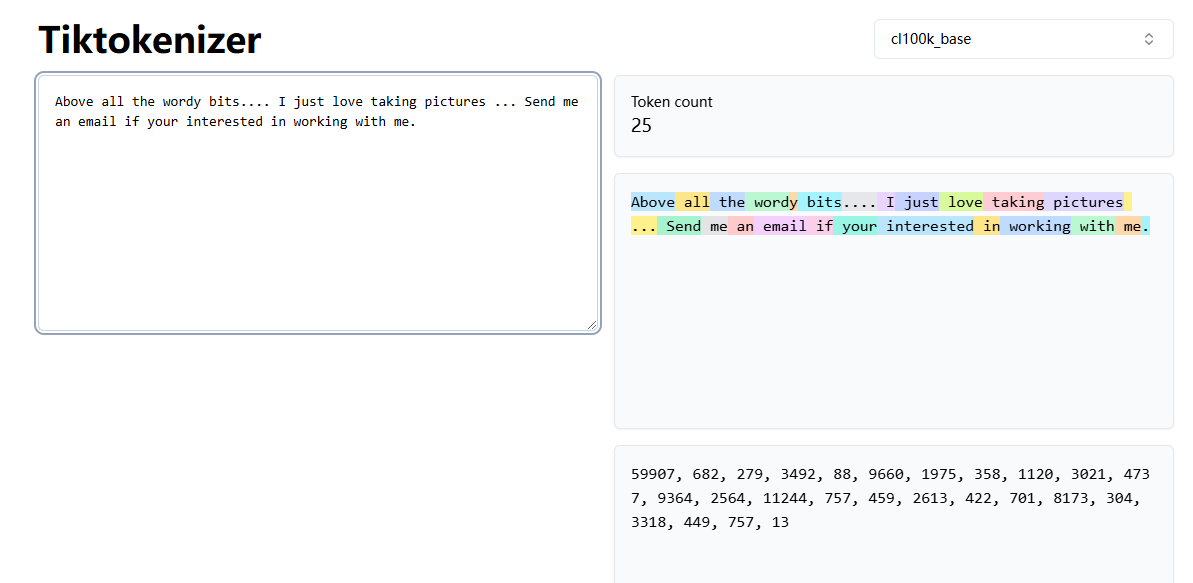
在上面的示例中,模型实际上看到的是 59907, 682, 279...,而模型的输出也是数字,再用同样的算法转换为人类可读的文本。
预训练模型
“GPT”指的是 “基于 Transformer 的生成式预训练模型” 。这个名称可以拆解为三个关键点:
生成式(Generative) :它根据已有的上下文生成文字。
预训练(Pre-trained) :它需要先在一个庞大的数据集上进行训练,这个过程帮助模型学习语言的规律。
Transformer:这是模型的具体结构名称,负责高效处理文本序列并捕捉上下文间的关系。
顾名思义,第一步就是基于之前提到的语料库来对模型进行预训练,这一过程可以让模型获得语料库中丰富的的知识。
训练流程示例:下一个单词预测
这是前文语料库中的一段文字:
I tend to specialise in shallow depth of field commercial and editorial images, recently I have been involved in portraiture and fashion as the technical challenges have been interesting to me. Most of my work is conducted on site and is taken "free style". I prefer to work this way, I "find" the image at the time of the event. I am passionate about the "feel" of an image, I love to produce images that evoke an emotion or question from the viewer. If you have something special and creative you wish to produce or take part in then please make contact. Above all the wordy bits.... I just love taking pictures ... Send me an email if you're interested in working with me.
训练的核心思路之一就是让模型学习“下一个词”或“下一个句子”的概率分布。例如,我们从上文中任意截取一段文字:
“recently I have been involved in portraiture and fashion as the technical challenges have been
interesting to me.”
把“recently... challenges have been”这一部分发送给模型,然后让模型猜测接下来的单词是什么。模型会返回一个概率列表,其中包含所有可能的单词以及它们的概率:
下一个单词 概率
good 3.50%
apple 20.10%
interesting 10.2%
...
根据上文,可以知道正确答案为 interesting,所以就告诉模型需要把 interesting 的概率调高一些,其他的单词概率调低一些,
下一个单词 概率
good 0.30%
apple 0.50%
interesting 40.40%
...
通过无数次这样的“下一个词”预测和纠正,模型会逐步学会哪种词汇在上下文里更合适、句子怎么组织才通顺。这样一来,模型就能够在看过足够多的文本之后,学到很多语言规律和事实知识。
现代的模型通常可以根据很长的前文来预测下一个单词,如 claude 3.5 sonnet 的上下文长度为 20 万 token, 也就是说这个模型有能力根据大约 20 万字的前文来预测下一个单词是什么。
当训练完成后,我们就得到一个“基础模型”(Base Model)。
这个时候,模型还只是一个预测器,它获得了语料库中的所有知识。给它一段文本,它会根据知识预测出下一个单词。
一个常见的误解是,模型一次性就能预测出整个句子或段落的答案。实际上,模型是逐词逐步生成答案的。比如,当你问它一个问题,它会根据上下文每次只预测一个词,然后程序把这个词加到句子中,再让模型根据这个句子预测下一个词。
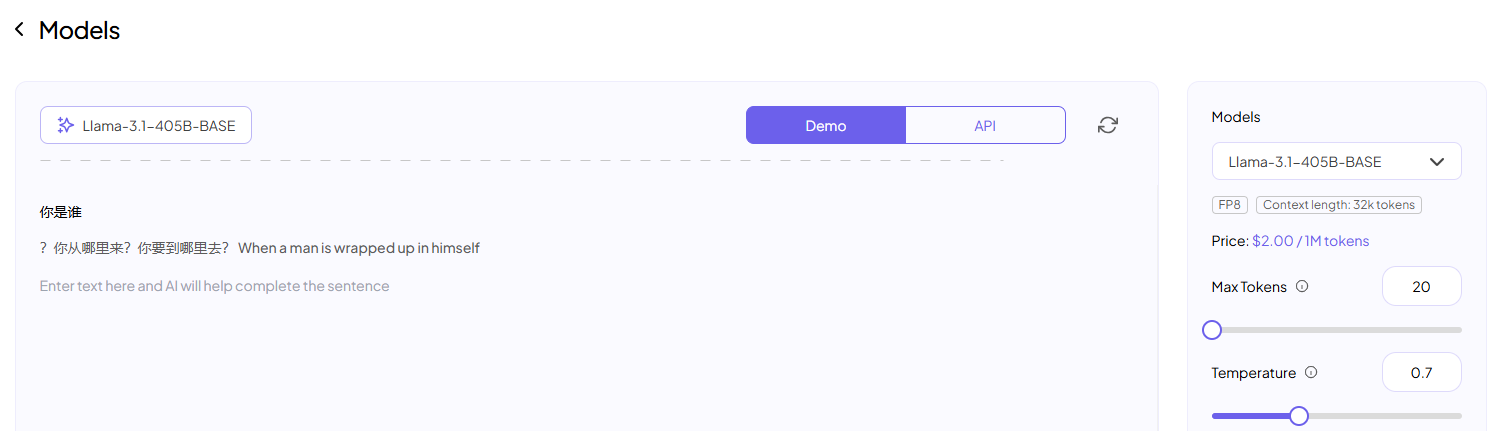
如上面这个模型,我在 Max Tokens 那里限制了最多补全 20 次,程序运行的过程如下:
你是谁 -> ?
你是谁? -> 你
你是谁?你 -> 从
你是谁?你从
...
这就是为什么与 ChatGPT 对话时,它会一个字一个字显示出来。
但是,这个模型还不能进行有效的对话。例如,如果我问它“你是谁”,它不会回答“我是 ChatGPT”,而是会尝试补全“?你从哪里来,你要到哪里去?”因为这个模型还没有“聊天”的概念。
把 Base 模型变成能聊天的 Chat 模型
那么,如何将这个基础模型转变为能够和你正常聊天的“智能助手”呢?这就需要 对话格式 和 人类示例 的帮助。
像 OpenAI 等公司会雇佣大量的人工专家,这些专家编写问题并给出对应的回答示范,进而构建一个人类专家的对话语料库,类似下面这样:
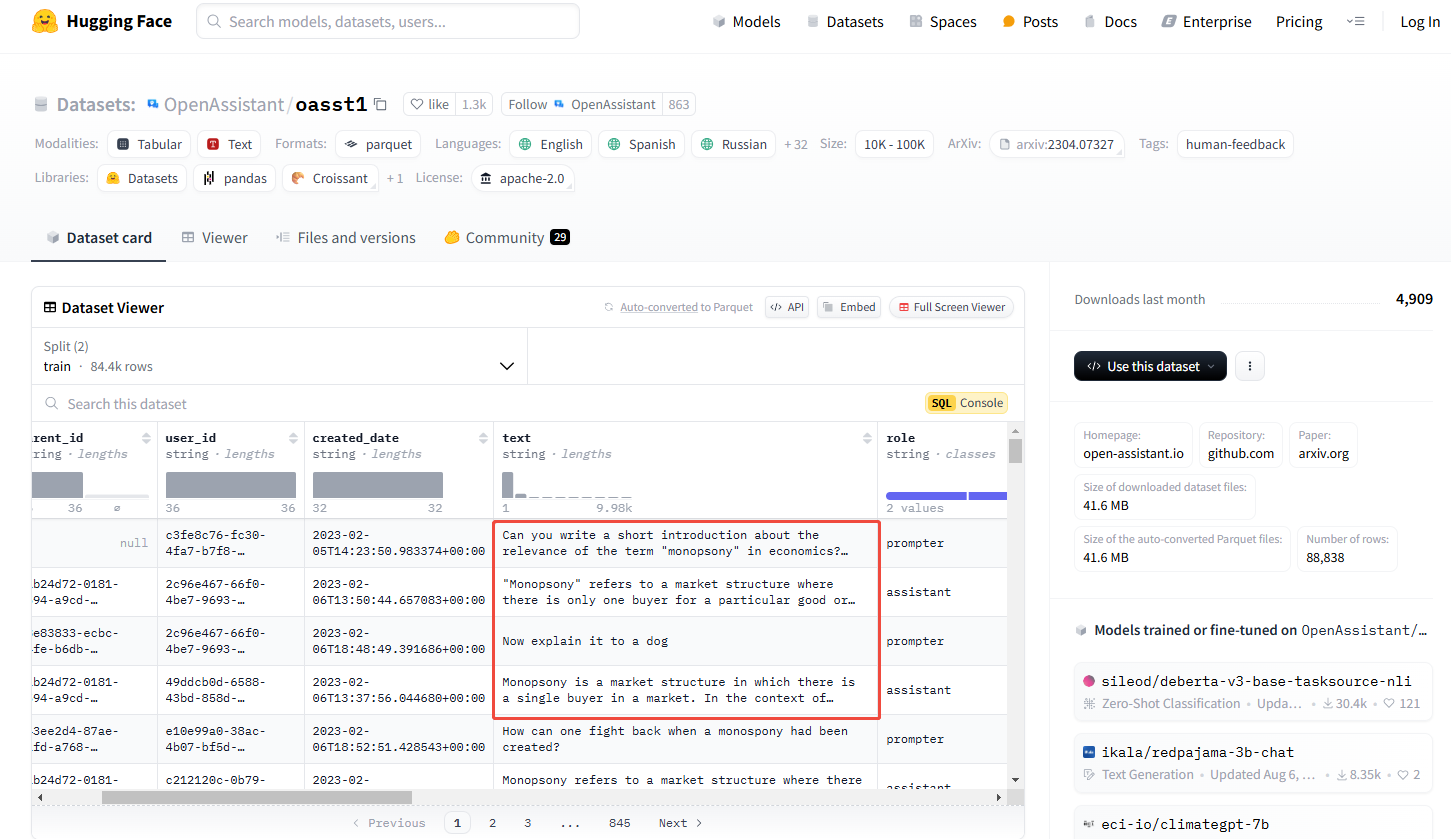
接下来,将这些语料通过特定格式发送给模型进行训练:

由于模型之前从未见过 <|im_start|> 和 <|im_end|> 这样的标签,在训练过程中,模型学会了在遇到这些标签时,以这种格式进行回答,并模仿人类的对话风格:
<|im_start|>assistant<|im_sep|>我是 ChatGPT<|im_end|>
当程序检测到 <|im_end|> 时,它知道这一句话已经结束,因此不会继续让模型补全。通过这种少量示例的训练,模型便能学习如何在这种格式下进行对话,最终将基础模型转变为能够进行流畅对话的 Chat 模型。
从这一角度来说,你可以把此时的模型看作“人类专家模拟器”,当你提出一个问题时,模型会基于“互联网语料库”中习得的知识,模仿“人类专家语料库”中习得的风格,来回复你的问题。
上下文(Context)
人类在对话时,会根据当前的谈话内容来理解和回应。比如:
人类: 我养了一只狗
人类: 它今天不太开心
即使第二句没有明确说明是谁不开心,我们也能从上下文理解"它"指的是狗。
大语言模型也是如此。当我们和模型对话时,之前的对话的全部内容会作为"上下文"一起传给模型:
<|im_start|>user<|im_sep|>
我养了一只狗
<|im_end|>
<|im_start|>assistant<|im_sep|>
真好,养狗是很有趣的体验。狗狗是什么品种呢?
<|im_end|>
<|im_start|>user<|im_sep|>
它今天不太开心
<|im_end|>
<|im_start|>assistant<|im_sep|>
模型能够理解"它"指的是狗,因为在之前的对话中已经提到过狗。这种依赖上下文的理解方式让对话更自然。
然而,上下文也有一定的限制:
长度限制:模型能够记住的上下文长度是有限的(例如,GPT-3.5最多为4k个token)。
时效性:每次对话结束后,上下文会被清空,下次对话需要重新开始。
幻觉
尽管模型通过大量的数据学习了许多知识,但它并不总是能够正确回答问题。有时,当模型遇到它不了解的事情时,它会自信地给出一个看似正确的答案,这种现象被称为“幻觉”。这种情况在早期模型中尤为常见。
当模型遇到它不理解的问题时,尽管模型内部的一些神经元可能意识到自己无法给出正确答案,但由于训练数据的风格通常是“自信地回答”,因此模型会在不知道答案时,仍然自信地编造一个答案。
为了让“幻觉”现象更易理解,以下是一些具体的示例:
幻觉示例
- 虚构引用和来源
人类: 请给我推荐一些关于人工智能的学术论文。
助手: 推荐您阅读 Johnson 等人2023年发表在 Nature 上的论文《The Future Impact of AI on Human Society》(doi: 10.1038/s41586-023-12345-6)...
[实际上这篇论文和DOI号都是模型编造的]
- 编造不存在的网址
人类: 想了解更多信息去哪里查询?
助手: 您可以访问 www.ai-research-center.org 了解更多详细信息。
[这个网址实际上并不存在]
- 错误的历史事实
人类: 第一台电子计算机是什么时候发明的?
助手: 第一台电子计算机 MARK-I 是由约翰·冯·诺依曼于1932年在普林斯顿大学发明的。
[这个说法混淆了多个历史事实]
减少大语言模型产生“幻觉”的方法
现在的模型在减少"幻觉"方面已有所改善,其中一个有效方法是:
首先准备一系列问题和对应的标准答案,通过测试找出模型容易产生错误回答或"幻觉"的问题。然后将这些问题的标准答案统一改写为"对不起,我不知道..."等诚实的回应,由此形成新的训练语料库。用这个经过处理的语料库重新训练模型,使其学会在面对不确定的问题时,能够坦诚地承认"我不知道",而不是随意作答。
搜索
大语言模型虽然学习了大量的知识,但仍然存在两个主要问题:
知识不够新:模型的知识都是截止到训练时的,训练之后发生的事情它就无法知晓了。
可能会胡说:有时候模型会自信满满地给出看似正确的答案,但实际上可能是错误的(即“幻觉”问题)。
为了解决这些问题,我们可以将类似 Google 的搜索工具与模型结合,用搜索引擎返回的知识给模型做参考,帮助模型作答。
注意模型不能直接访问互联网,我们做的只是教会如何它与搜索工具进行交互。具体做法是准备这样的训练数据:
原来的对话是这样的:
<|im_start|>user<|im_sep|>
2024年世界杯冠军是谁?
<|im_end|>
<|im_start|>assistant<|im_sep|>
对不起,我不知道。
<|im_end|>
改为如下:
<|im_start|>user<|im_sep|>
2024年世界杯冠军是谁?
<|im_end|>
<|im_start|>assistant<|im_sep|>
这个我得查一下最新的体育赛事信息。
<|search|>2024年世界杯冠军队|2024 World Cup winner<|/search|>
<|im_end|>
用这种语料训练后,模型就学会了:
知道何时需要查找最新信息。
主动提出要进行搜索。
正确生成搜索关键词。
实际应用中,流程大致如下:
用户询问:特斯拉最新股价是多少?
模型发现需要最新的数据,于是返回一个搜索标记,并带上搜索关键词:
<|im_start|>user<|im_sep|>
特斯拉最新股价是多少?
<|im_end|>
<|im_start|>assistant<|im_sep|>
让我查查最新股价。
<|search|>Tesla stock price today|特斯拉股票实时价格<|/search|>
<|im_end|>
程序看到这个搜索标记,就会去谷歌搜索这些关键词。
搜索引擎返回如下结果
特斯拉(TSLA)股价为193.57美元(2024年2月8日收盘价)
- 程序将谷歌搜到的结果放进对话,继续调用模型补全:
<|im_start|>user<|im_sep|>
特斯拉最新股价是多少?
<|im_end|>
<|im_start|>assistant<|im_sep|>
让我查查最新股价。
<|search|>Tesla stock price today|特斯拉股票实时价格<|/search|>
<|im_end|>
<|im_start|>system<|im_sep|>
搜索结果:特斯拉(TSLA)股价为193.57美元(2024年2月8日收盘价)
<|im_end|>
- 模型看到搜索结果,就能回答:
<|im_start|>user<|im_sep|>
特斯拉最新股价是多少?
<|im_end|>
<|im_start|>assistant<|im_sep|>
让我查查最新股价。
<|search|>Tesla stock price today|特斯拉股票实时价格<|/search|>
<|im_end|>
<|im_start|>system<|im_sep|>
搜索结果:特斯拉(TSLA)股价为193.57美元(2024年2月8日收盘价)
<|im_end|>
<|im_start|>assistant<|im_sep|>
根据最新数据,特斯拉股价是193.57美元(2024年2月8日收盘价)。
<|im_end|>
通过这些方式,AI能够更加准确和实时地回答问题。